LocoFormer: Generalist Locomotion via
Long-Context Adaptation

CoRL 2025 (Best Paper Award Finalist)
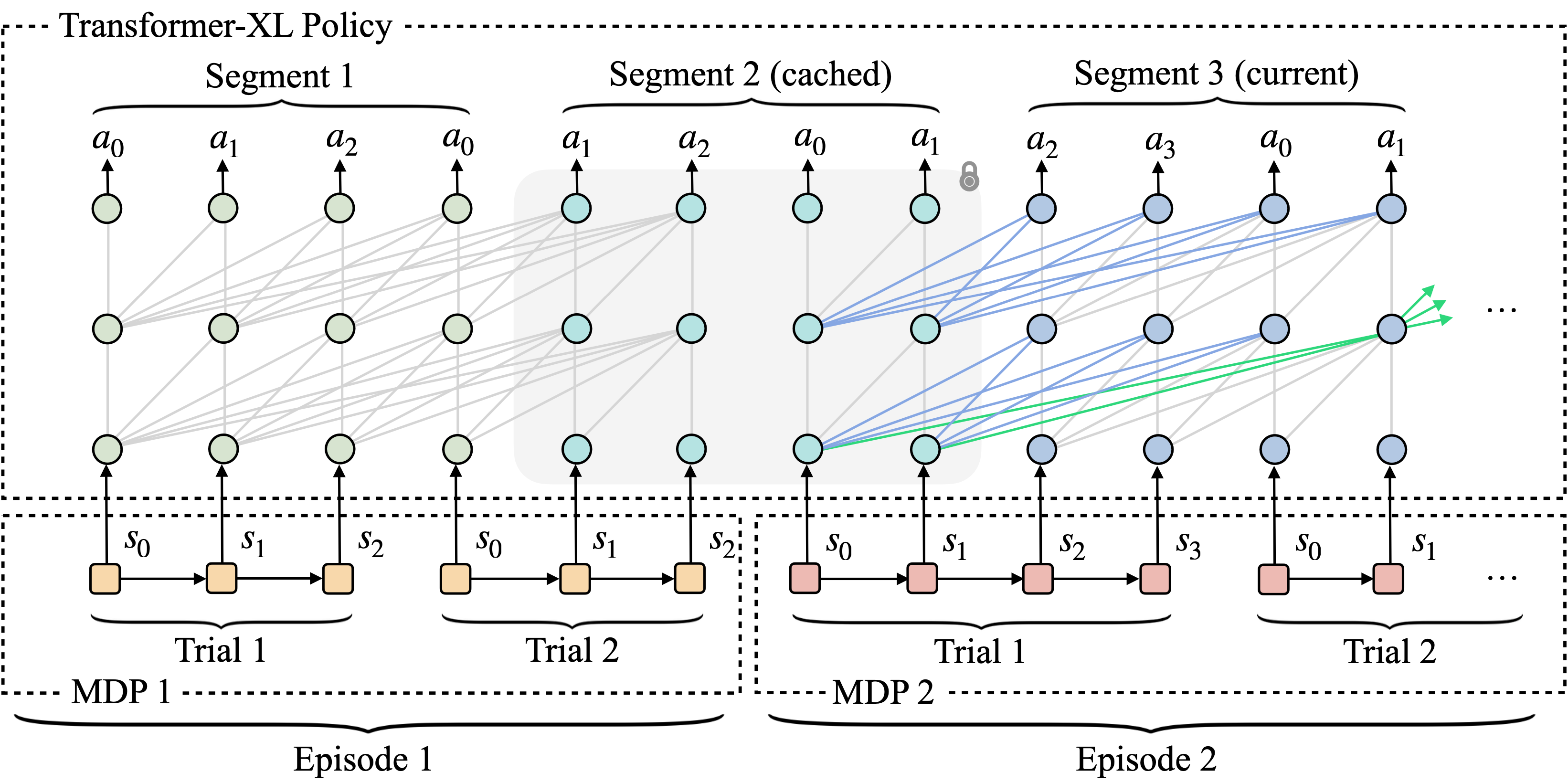
Modern locomotion controllers are manually tuned for specific embodiments. We present LocoFormer, a generalist omni-bodied locomotion model that can control previously unseen legged and wheeled robots, even without precise knowledge of their kinematics. LocoFormer is able to adapt to changes in morphology and dynamics at test time. We find that two key choices enable adaptation. First, we train massive scale RL on procedurally generated robots with aggressive domain randomization. Second, in contrast to previous policies that are myopic with short context lengths, we extend context by orders of magnitude to span episode boundaries. We deploy the same LocoFormer to varied robots and show robust control even with large disturbances such as weight change and motor failures. In extreme scenarios, we see emergent adaptation across episodes, LocoFormer learns from falls in early episodes to improve control strategies in later ones. We believe that this simple, yet general recipe can be used to train foundation models for other robotic skills in the future.
@inproceedings{liulocoformer,
title={LocoFormer: Generalist Locomotion via Long-context Adaptation},
author={Liu, Min and Pathak, Deepak and Agarwal, Ananye},
booktitle={9th Annual Conference on Robot Learning},
year={2025}
}